

The Art of Human-Machine Language
Communication is an integral part of our lives as humans. With communication, people collaborate and co-exist, with human language being the primary communication tool. The pioneers of modern technological devices grasped the essence of communication and provided tools for such dialogue to take place between humans and machines. The computer, for example, has input devices like the keyboard and mouse that facilitate communication.
These devices weren’t necessarily natural to people. They were more mechanical than fluid, similar to how we communicate with our voice. This absence led to the development of Computational Linguistics, now known as Natural Language Processing (NLP). NLP is a subfield of linguistics, computer science, and artificial intelligence (AI) that allow computers to understand written and spoken words as much as humans can.
NLP is used in technologies everywhere around us. From Amazon’s Alexa to spam detection in emails. In this article, we’ll understand the evolution of NLP and how it has affected our everyday lives.
Prerequisites: This article isn’t of a strictly technical nature. But rather designed as an informative piece on Natural Language Processing and its many advances through time.
Outline:
Evolution of Natural Language Processing
1950s: Machine Translation
1960s: SHRDLU and ELIZA
1980s: Computational Linguistics
1990s: Statistical Machine Learning
2010s: Neural Networks
Everyday uses of Natural Language Processing
Spam Detection
Speech Recognition
Grammar Checker
Chatbots and Voice Assistants
Machine Translation
Evolution of Natural Language Processing.
1950s: Machine Translation

The Georgetown-IBM experiment was conducted by Georgetown University and International Business Machine (IBM) in New York, in January 1954, during the second world war. The researchers designed it to be small-scale, consisting of 250 lexical items (stems and endings) and six “grammar” rules aimed at translating Russian to English and proving the feasibility of machine translation. The experiment attracted funding and showed promising signs of good quality automatic translation but failed to do so, as discovered by ALPAC, a committee set up by the funders to investigate the growth of the experiment. Despite its failure, the Georgetown experiment was the first attempt at machines in understanding human language. And paved the way for future developments.
1960s: SHRDLU and ELIZA
ELIZA
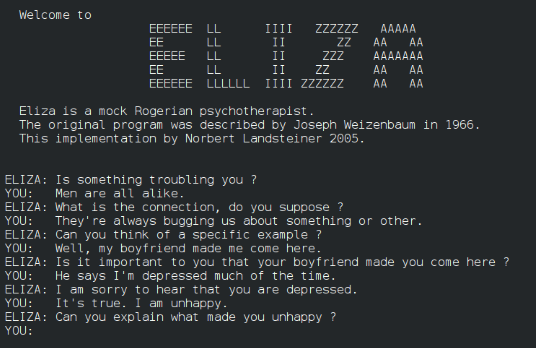
From 1964 to 1966, Joseph Weizenbaum, a professor at MIT Artificial Intelligence Laboratory, created ELIZA. ELIZA was a natural language processing computer program built in the form of a chatbot. The chatbot understood text using a pattern matching and substituting methodology. First, it selected the main words in a sentence and gave a reply using those words giving the illusion that the program was able to engage in a conversation like a Rogerian psychotherapist. Thereby deceiving its users that it had human attributes, including his secretary, who asked to be left alone to speak with ELIZA. In reality, the program had no contextual understanding of the input text. To explore the workings of Eliza, consult the demo here.
SHRDLU
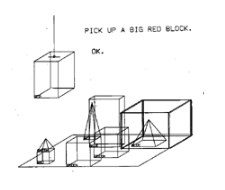
In 1970, Terry Winograd built SHRDLU, an early natural language understanding computer program at MIT Artificial Intelligence Laboratory. The program could understand users’ input and perform the given instructions, such as moving and stacking blocks in a blocks world. Despite being a rule-based system, SHRDLU gave an illusion of intelligence by being able to understand, reply, and carry out instructions in natural language.
1980s — 1990ss: Computational Linguistics and Statistical Machine Learning
Before the 1980s, there had not been any substantial improvement in the growth of Natural Language Processing, with most inventions operating on complex rule-based systems which were difficult to build. However, starting in the late 1980s, with the introduction of machine learning algorithms for language processing, NLP took a new shape. The reason for this was an increase in computational power and the gradual lessening dominance of the Chomskyan theories of linguistics. This discouraged the use of corpus linguistics that underlies the machine learning approach to language processing.
2000s and beyond: Neural Networks

The introduction of neural networks, and the internet making large amounts of data readily available to be trained, truly revolutionized the NLP industry. The industry has gone from using one-hot encoding of words to word embeddings like Word2Vec to capture meaning more precisely. After Word2Vec, came the use of language models, which were pre-trained to understand the meaning of words. These models initially started with 100 to 300 million parameters (BERT and ELMo) but have now crossed the trillion parameter mark (Switch Transformer and Bagualu).
Everyday Uses of Natural Language Processing
Email Spam Detection
Spam refers to unwanted and unsolicited messages sent in bulk to exploit the recipients of either personal identity (identity theft) or money. Statistics by Spamlaws state that 45% of all emails are scams, with advertisements, adult-related content, and financial matters making up most of them.
Before NLP, software companies used rule-based systems to detect spam emails. This method wasn’t adequate as it led to the false classification of emails. Also, scammers could easily avoid using such words when sending an email.
With NLP, machine learning models can identify patterns used in spam emails and classify them correctly. In 2017, Google stated that its machine learning models can now detect spam and phishing emails with 99.9% accuracy, showing how far the system has come.
Speech Recognition

“Ok, Google” and “Hey Siri” are phrases that demonstrate the use of speech recognition in our everyday life. Speech recognition or speech-to-text is the ability of a computer program to translate spoken words into text. It is the foundation of virtual home assistants like Amazon’s Alexa, Apple’s Siri, Google’s Assistant, and Microsoft’s Cortana.
With speech recognition, NLP-based software can understand human words and perform actions based on the speech, such as- playing music, booking a car ride, or setting up a reservation.
Grammar Checker

Grammarly is an example of software that applies NLP to checking grammar, spelling, passive voices, and common grammatical errors. The machine learning models check for grammar mistakes and suggest a correct replacement. Microsoft Word and Google Docs also provide grammar checking for text.
Chatbots

Chatbots are computer programs that can hold human conversations through voice or text-based inputs. Chatbot, short for chatterbot, can be used in business to handle customer requests or complaints that do not require human assistance. These programs can operate with a set of guidelines or with machine learning.
When using a set of guidelines, chatbots are limited and are only as intelligent as their programming code. But with machine learning, chatbots can analyze input text/commands and reply intelligently based on the previous inputs it has handled before. The chatbot model also becomes more intelligent as it deals with more text over time.
Machine Translation
Machine Translation, often abbreviated as MT, involves translating text from one language to another. As stated at the beginning of this article, machine translation started in the 1950s with a rule-based system but later transitioned to the use of statistical models for translation. Both methods were slow and inaccurate to use.
With the introduction of neural networks, machine translation became more accurate as machine learning models were continuously learning and faster, because the translation of the text was less mechanical and not highly dependent on programming code.
Google Translate, DeepL Translator, Bing Microsoft Translator, SYSTRANS Translate, and Amazon Translate are some of the best machine translation apps in the market.
Conclusion
It’s a fact- Natural Language Processing has come a long way since its inception in 1954. Nevertheless, we have only just begun to scratch the surface of what is possible. In the future, big tech companies like Google, Amazon, Meta, OpenAI, and Apple will develop more advanced algorithms by heavily investing in their NLP applications. In doing so, they will conceptualize what today lives as a mere schematic.
