Glossary
Below we have listed our Data Glossary terms to help assist you on your data journey.
A
A/B testing
A/B testing, also known as split testing, refers to a randomized experimentation process wherein two or more versions of a variable (web page, page element, etc.) are shown to different segments of website visitors at the same time to determine which version leaves the maximum impact and drives business metrics
ACID compliance
OLTP systems must ensure that the entire transaction is recorded correctly. A transaction is recorded correctly only if all the steps involved are executed and recorded. If there is any error in any one of the steps, the entire transaction must be aborted and all the steps must be deleted from the system. Thus, OLTP systems must comply with atomic, consistent, isolated, and durable (ACID) properties to ensure the accuracy of the data in the system.
Atomic: atomicity controls guarantee that all the steps in a transaction are completed successfully as a group. That is, if any steps in a transactions fail, all other steps must also fail or be reverted. The successful completion of a transaction is called commit. The failure of a transaction is called abort.
Consistent: the transaction preserves the internal consistency of the database.
Isolated: the transaction executes as if it were running alone, with no other transactions. That is, the effect of running a set of transactions is the same as running them one at a time. This bahavior is called serializability and is usually implemented by locking the specific rows in the table.
Durable: the transaction's result will not be lost in a failure.
Actionable intelligence
AI-as-a-service (AIaaS)
Algorithms
Algorithum refers to a sequence of finite steps to solve a particular problem
Amazon Web Services
Ambient intelligence
Analytical data
Analytical data is used by businesses to find insights about customer behavior, product performance, and forecasting. It includes data collected over a period of time and is usually stored in OLAP (Online Analytical Processing) systems, warehouses, or data lakes.
Apache Hadoop
Apache Hadoop is an open source software framework that provides highly reliable distributed processing of large data sets using simple programming models. Hadoop, known for its scalability, is built on clusters of commodity computers, providing a cost-effective solution for storing and processing massive amounts of structured, semi-strucuted and unstructured data with no format requirements.
Hadoop can also be installed on cloud servers to better manage the compute and storage resources required for big data. Leading cloud vendors such as Amazon Web Services (AWS) and Microsoft Azure offer solutions. Cloudera supports Hadoop workloads both on-premises and in the cloud, including options for one or more public cloud environments from multiple vendors.
Apache Spark
Apache Spark (Spark) is an open source data-proprocessing engine for large data sets. It is designed to deliver the computational speed, scalability, and programmability required for Big Data—specifically for streaming data, graph data, machine learning, and artificial intelligence (AI) applications.
Spark's analytics engine processes data 10 to 100 times faster than alternatives. It scales by distributing processing work across large clusters of computers, with built-in parallelism and fault tolerance. It even includes APIs for programming languages that are popular among analysts and data scientists, including Scala, Java, Python, and R.
Spark is often compared to Apache Hadoop, and specifically to MapReduce, Hadoop's native data-processing component. The main difference between Spark and MapReduce is that Spark processes and keeps the data in memory for subsequent steps—without writing to or reading from disk—which results in dramatically faster processing speeds.
Spark was developed in 2009 at UC Berkeley. Today, it's maintained by the Apache Software Foundation and boasts the largest open source community in big data, with over 1,000 contributors. It's also included as a core component of several commercial big data offerings.
Apache Spark Mllib
One of the critical capabilities of Apache Spark is the machine learning abilities available in the Spark MLlib. The Apache Spark MLlib provides an out-of-the-box solution for doing classification and regression, collaborative filtering, clustering, distributed linear algebra, decision trees, random forests, gradient-boosted trees, frequent pattern mining, evaluation metrics, and statistics. The capabilities of the MLlib, combined with the various data types Spark can handle, make Apache Spark an indispensable Big Data tool.
Application development
Application development portfolio
Artificial intelligence
Artificial intelligence (AI) is the ability of a computer or a robot controlled by a computer to do tasks that are usually done by humans because they require human intelligence and discernment. Although there are no Ais that can perform the wide variety of tasks an ordinary human can do, some AIs can match humans in specific tasks.
Association rules
An association rule is a rule-based method for finding relationships between variables in a given dataset. These methods are frequently used for market basket analysis, allowing companies to better understand relationships between different products. Understanding consumption habits of customers enables businesses to develop better cross-selling strategies and recommendation engines.
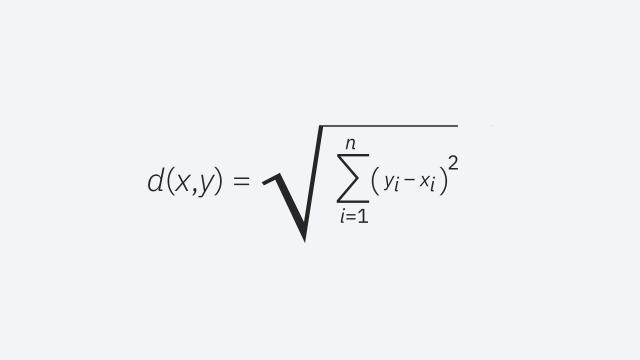
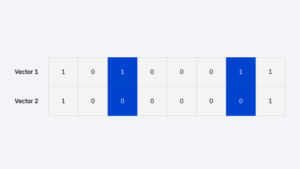
 As an example, if you had the following strings, the hamming distance would be 2 since only two of the values differ.
As an example, if you had the following strings, the hamming distance would be 2 since only two of the values differ.